An IT Leaders Guide to AI & Machine Learning
From fundamental concepts, approaches and use cases, to industry examples of implementations across data, vision and language.
*Updated February 2025
Note: None of this content was generated by ChatGPT. Only humans.
Introduction
Recent advancements in AI have shown how the technology has the ability to significantly impact industries globally in the near to medium term. With rapid advancements in the ability to process and generate complex data, most recently around language and vision, organisations will be able to unlock new levels of efficiency and productivity in their business operations.
This has been driven by a combination of improvements in model architectures, developments in supporting tools and services, increase in compute processing capacity and increase in data available to process.
The technology has also moved away from being a field purely accessible to specialists, to one accessible to people with varying degrees of technical capability, thanks to the abundance of products, libraries and services now available.
However, due to the broad range of methods, models and approaches available, many organisations are struggling to match a technology solution to a real-world use case for improvement.
This guide aims to demystify AI and machine learning and equip organisations with the knowledge needed to navigate this evolving landscape. This understanding will empower business leaders to make informed decisions and capitalise on the potential of artificial intelligence.
- Introduction
- Background
- Definitions
- A brief history
- The current state of AI
- Data for AI
- Pillar 1: Clear & Shared Vision
- Pillar 2: Delivery vs. Empowerment
- Pillar 3: Infrastructure & Scalability
- Pillar 4: Quality, Consistency & Accessibility
- Pillar 5: Governance & Security
- Pillar 6: Iteration & Experimentation
- Pillar 7: Testing & Monitoring
- Pillar 8: Managing AI & Data Technical Debt
- Getting Started with AI
- Data Types
- Data Outputs
- Model Selection
- Approach I - Cloud Services
- How to Get Started
- Benefits
- Considerations
- Approach II - Defining Your Own Model
- How to Get Started
- Benefits
- Considerations
- Hosting a Model
- Cloud
- On-premises
- Containers
- Maintaining and Retraining Models
- Appendix 1 - Example Cloud Service Architecture (Azure AI)
- Azure Machine Learning
- Azure Cognitive Services
- Azure Applied AI Services
- Azure AI Cloud Services Breakdown
- Appendix 2 - Industry Case Studies
- 1 - Planning Optimisation
- 2 - Outlier Detection and Classification
- 3 - Image Classification
- 4 - Custom Software Builder
- 5 - AI WhatsApp Chatbot
- Solution
- How it Works
- The Benefits
- Glossary
- Download
Background
Definitions
AI can be broadly understood as any system that exhibits behaviour or performs tasks that typically require human intelligence. It encompasses various approaches, including machine learning, expert systems, rule-based systems and symbolic reasoning. Machine learning, a subset of AI, uses trained models to interpret and analyse complex data sets.

Trained models are the result of a learning process where the model is exposed to data and adjusts its internal parameters to capture patterns and relationships within the data. This learning process can be categorised into three types: supervised learning, unsupervised learning and reinforcement learning.
Supervised learning
Supervised learning involves training models using input and output data. Learning from these examples, the model is then able to adapt to changing situations and make predictions on unseen data.

Unsupervised learning
Unsupervised learning, alternatively, defines from unlabelled data. This enables algorithms to learn autonomously and uncover patterns and structures in data without predefined labels or explicit guidance.
Reinforcement learning
Reinforcement learning involves an intelligent agent being trained to make decisions based on feedback. The agent receives feedback through either rewards or penalties based on its actions. Feedback can then be used to improve the model's decision-making ability.
A brief history
Early advancements in Artificial Intelligence were based on logic-based reasoning. This includes expert systems and heuristic models which rely heavily on statistical methods to solve complex problems in specific domains. Where machine learning is focused more on extracting information from data sets, these rule engines rely on the rules that are input.
Over time, these approaches have been complemented, and replaced by, more advanced techniques. Machine learning algorithms have proven impressive in their capacity to learn from data and make predictions by identifying patterns. What makes systems powered by machine learning so powerful is their ability to learn without being as dependent on human intervention.
As machine learning has advanced so too has this ability to learn independently. Artificial neural networks mimic the structure of the human brain to process and transmit information. Consisting of interconnected nodes, these networks use activation functions to determine the output of each neuron. By propagating information forward and backward through the network, they learn to recognise patterns, classify data and make sophisticated predictions. This process replicates the multifaceted cognitive processes of the human brain.
Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) have played a significant role in how systems can process data related to image and speech, respectively. CNNs are mainly used for processing grid-like data, such as the pixels in an image. RNNs, on the other hand, are ideal for processing sequential data, where how elements are ordered is important.
These multi layered neural networks are encompassed by deep learning, an advanced form of machine learning that enables systems to learn increasingly complex representations of data. This subset of machine learning has led to breakthroughs in the way that models can process image, speech and text.
The current state of AI
Today, AI can perform a wide range of complex tasks that were once considered exclusive to human intelligence, with proficiency in natural language processing, image and speech recognition. At the peak of these advancements are transformers, which were initially proposed in Google's seminal research paper “Attention is All You Need”. This research introduced a novel architecture that is distinguished by its ability to process input sequences in parallel.
Unlike previous approaches, transformers do not rely on sequential processing. These models, instead, utilise self-attention mechanisms. Self-attention allows the model to capture relationships between different elements within a sequence by assigning importance weights to each element based on its relevance to other elements. This mechanism enables transformers to process the entire sequence in parallel, which makes them more efficient and effective in capturing long-range dependencies and contextual information.
Transformers have been particularly successful in tasks like machine translation, understanding human language and text generation. They have enabled the development of large-scale language models like OpenAI's Chat GPT and Google Bard, natural language processing tools that demonstrate impressive capabilities in generating coherent and contextually relevant text.
With different ways to leverage these algorithms and technologies, it can be difficult to know which is the best option and how you can get started. In the following sections we look at some of the key considerations for getting started with your AI projects.
Data for AI
Organisations have various factors to consider when beginning AI and machine learning projects, from defining the processes, people and data that fall within the scope to choosing the methods and technology to implement. All AI and machine learning projects depend on strong data foundations to function effectively, underpinned by a structured approach to data across the organisation.
In this section we discuss a framework made up of eight pillars for building reliable data foundations that are AI-ready.
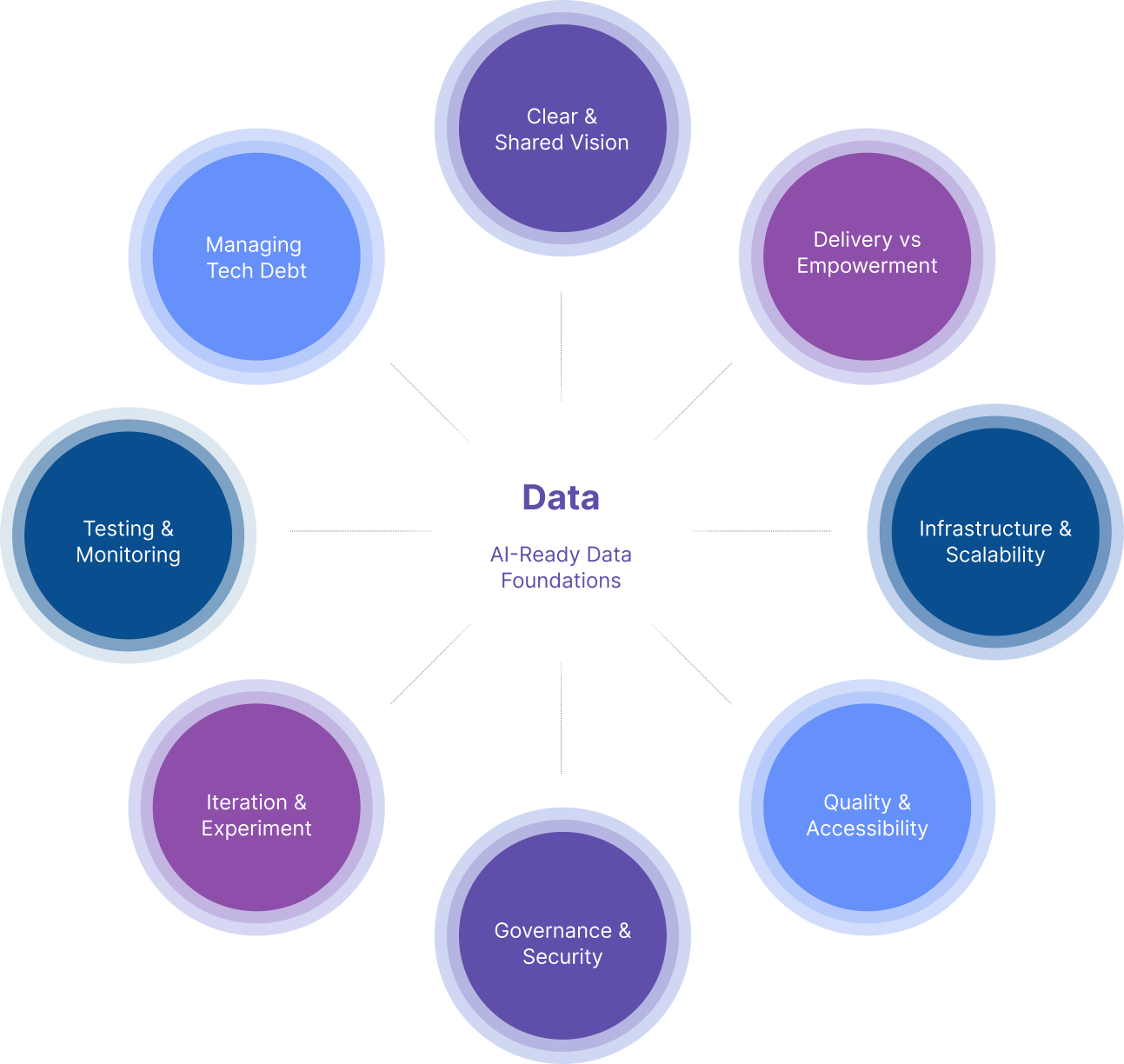
Pillar 1: Clear & Shared Vision
People, teams & culture
Aligning Goals
Aligning your data strategy with your organisation's overarching goals ensures that data initiatives directly support business outcomes. Clear objectives help the data team understand how their work fits into the broader picture, whether it’s driving operational efficiencies, enhancing customer experiences or enabling innovation.
Instilling a Data-Driven Culture
Building a data-driven culture means embedding data at the heart of decision-making. A culture of collaboration, trust and empowerment ensures that all stakeholders, from leadership to individual contributors, view data as a strategic asset. This cultural shift is vital for the successful adoption of AI and other data-driven technologies.
Enabling Cross-Functional Teams
To break down silos and drive collective success, cross-functional teams are essential. Collaboration between IT, business and data teams ensures that the data strategy is comprehensive and aligns with the unique needs of different departments. When teams work together, data insights are more effectively harnessed and implemented.
Establishing Clear Metrics
Defining shared vision and measurable milestones with accountability is key to tracking progress. Setting clear metrics allows organisations to measure success, identify gaps and iterate effectively. These metrics can range from business outcomes (e.g. revenue growth or cost savings) to technical performance indicators (e.g. data quality or model accuracy).
Pillar 2: Delivery vs. Empowerment
Creativity, ownership & accountability
Balancing Control vs. Creativity
Balancing central control and decentralised creativity ensures that organisations remain agile while maintaining consistency. While central control over data policies and strategies provides structure, decentralised creativity empowers teams to innovate and experiment. Striking this balance allows organisations to be both efficient and innovative in their approach to AI and data management.
Creating Sandboxes
Providing safe spaces, or sandboxes, for experimentation enables teams to explore new ideas without fear of disrupting live systems. These environments allow rapid prototyping, where AI and machine learning concepts can be tested, refined and validated, before scaling them across the organisation. Sandboxes encourage experimentation while protecting critical operations.
Establishing Ownership and Accountability
Empowering teams also means giving them ownership of data and AI projects. By providing clear ownership, teams are held accountable for delivering results and continuously improving the system. Ownership fosters a sense of responsibility, drives motivation and helps ensure that data and AI initiatives are aligned with organisational goals.
Empowering Decision-Making
Decentralising decision-making allows teams closer to the data to make informed decisions quickly. By equipping teams with the tools and resources they need, organisations enable them to take ownership of both the technology and the outcomes, leading to more rapid and impactful results.
Pillar 3: Infrastructure & Scalability
Data volume, processing and storage
Understanding Data Flows (Batch vs. Real-Time)
Understanding how data will flow through your systems – whether batch processing or real-time pipelines – affects infrastructure decisions. Real-time data is often necessary for applications like using AI for customer personalisation or operational monitoring, while batch processing works better for less time-sensitive tasks like periodic reporting.
Identifying Bottlenecks
As organisations scale, bottlenecks in data processing and infrastructure can impede performance. By identifying potential bottlenecks early – whether in data ingestion, processing or storage – organisations can plan solutions that mitigate these issues before they affect larger systems. Effective planning ensures smooth scaling as data volumes increase.
Weighing Cloud, On-Premises or Hybrid Solutions
The choice of infrastructure, whether cloud, on-premises or hybrid, determines how scalable your data systems can be. Cloud solutions offer flexibility and scalability, while on-premises setups may provide more control over data privacy. A hybrid approach offers the best of both worlds, allowing businesses to choose the most appropriate infrastructure for each use case.
Future-Proofing Solutions
As AI systems grow, so too will the demand for data. Infrastructure decisions should account for future scalability. Planning for future data volumes and processing needs ensures that the organisation is prepared to handle increased demand without significant rework or disruption.
Pillar 4: Quality, Consistency & Accessibility
Cleansing, analysis & volatility
Data Quality
High-quality data is critical for accurate AI predictions and insights. This involves cleansing, correcting and validating data before it’s used for training models. Ensuring data quality early in the process prevents the compounding of errors that can skew results and decrease model effectiveness.
Data Consolidation
Consolidating data into a central repository, such as a data warehouse or lake, ensures that it is accessible for analysis and AI model training. Master Data Management strategies help organise and synchronise data, making it easier to derive insights and avoid inconsistencies across different systems.
Data Volatility
Understanding the volatility of your data is essential for maintaining its relevance. Some data changes frequently (e.g. customer behaviour), while other data remains relatively stable (e.g. product specifications). Tracking the rate of change in data helps to ensure that models remain accurate and that the data is continually updated to reflect real-world conditions.
Data Accessibility
Ensuring data is easily accessible to the teams and systems that need it is crucial for operational efficiency. This involves organising data in ways that align with user needs and providing appropriate access controls to safeguard sensitive information. Properly structured data allows teams to easily retrieve and use it without unnecessary friction.
Pillar 5: Governance & Security
Responsibilities, permissions & security
Defining Data Ownership
Clear ownership and responsibility for data are vital for ensuring that data is properly managed. Assigning owners ensures accountability for data quality, security and compliance. Data ownership also helps to prevent data silos and guarantees that stakeholders across the organisation understand their role in managing data.
Understanding Data Lineage
Understanding the lineage of data – where it comes from, how it’s transformed, and how it moves through the system – is crucial for transparency and trust. Tracking data lineage provides visibility into data flows, ensuring that its integrity is maintained throughout the lifecycle and enabling organisations to trace back errors or issues.
Establishing Permissions
Establishing appropriate permissions and access control mechanisms ensures that only authorised individuals or systems can access or manipulate data. Role-based access helps maintain security while allowing necessary access to teams across departments. Permissions are essential for preventing data breaches and ensuring compliance with privacy regulations.
Ensuring Privacy & Compliance
As organisations collect and process vast amounts of data, compliance with data privacy regulations (e.g. GDPR, CCPA) is paramount. Data governance frameworks should incorporate privacy protections and ensure that data handling aligns with legal and regulatory requirements. Strong governance guarantees that data is used responsibly, maintaining both trust and compliance.
Pillar 6: Iteration & Experimentation
Feasibility, performance and improvement
Starting Small & Scaling
AI projects should begin with small, manageable initiatives to prove feasibility and gain insights. Early-stage experiments or Proof-of-Concept (PoC) projects allow teams to test ideas with minimal risk and gather valuable lessons. Once proven, these initiatives can be scaled to more significant projects.
Undertaking Exploratory Data Analysis
Exploratory Data Analysis (EDA) helps to uncover relationships, trends and features within the data. By thoroughly understanding the data before model development, teams can make informed decisions about which variables to include and how to structure their models.
Validating Feasibility & PoCs
Feasibility studies and PoCs validate the potential of data-driven solutions before full-scale implementation. These projects help to confirm that the data supports the use case and that the model will likely achieve the desired outcomes. PoCs also help identify roadblocks or limitations early in the process.
Establishing Feedback Loops
Feedback loops ensure continuous improvement in data and models. As AI models are deployed, they must be monitored and refined based on performance. These loops allow for adjustments and help the organisation adapt as new data or challenges emerge.
Pillar 7: Testing & Monitoring
Validation, accuracy & risk mitigation
Balancing Automation vs. Manual
Finding the right balance between manual and automated testing is crucial. Automated tests are faster and can handle large datasets, but manual checks ensure domain-specific issues are not overlooked. Combining both methods ensures thorough validation of AI models.
Understanding Risk
It's essential to understand the risks of automation, such as model bias, lack of explainability or errors in automated test cases. Proper testing ensures that these risks are identified and mitigated before models are deployed.
Establishing a Testing Strategy
A robust testing strategy should be planned early in the project. This includes aligning testing with the domain and technology, ensuring that AI models meet business requirements and are free from bias or error.
Continuous Production Monitoring
Continuous monitoring of AI models in production helps to identify performance issues, such as model drift, early. By actively monitoring models post-deployment, businesses can quickly detect and address problems whilst rolling back to a stable version, ensuring the model continues to deliver accurate results over time.
Pillar 8: Managing AI & Data Technical Debt
Cost management, maintenance & optimisation
Avoiding Bloated LLMs
Large Language Models (LLMs) and other complex AI models can quickly become bloated, leading to inefficiencies and high operational costs. Ensuring models are modular and optimised helps avoid unnecessary complexity and keeps them lean.
Decoupling & Modularity
Building AI systems with decoupled architectures allows for greater flexibility and scalability. Modularity ensures that components can be independently updated or replaced without disrupting the entire system, making it easier to manage long-term technical debt.
Delivering Debt Maintenance
Managing technical debt involves regularly refactoring and optimising AI systems to avoid stagnation. By investing time in maintaining systems, organisations can prevent the accumulation of debt that would otherwise result in higher operational costs and inefficiencies.
Read more about Designing Scalable Data Architectures for AI.
Getting Started with AI
In order to get started with initial AI and machine learning projects, we have distilled approaches into three key considerations:
- What type of data are you working with?
- Are you gaining insights from data or generating data?
- What model should you use?
Data Types
What type of data are you working with?
Are you working with financial data, user activity, volumes of text, images or something else? Is your data structured or unstructured? For example, your organisation may want to analyse online customer behaviour to inform marketing strategies. The data involved would consist of structured data such as user demographics, browsing preferences and purchase records. In this scenario a model could be used to capture preferences in future behaviour.
Alternatively, if you want to visually identify stock, then your data will be images. Many image classifiers have been pre-trained, where a model that has already been trained on a dataset. Using pre-trained models can allow organisations to begin quickly leveraging AI technology without having to invest in training data and models from scratch. Pre-trained models like those offered in Azure Custom Vision and AWS Rekognition provide a strong foundation for these scenarios, with pre-trained models for image classification and object detection, specifically.
Also consider the data that you would receive from your solution; how will you evaluate the output? If you decide to use a language model to process and generate text (e.g. a chatbot), then it is important to consider the challenges that come with evaluating its responses. Large language models can be difficult to test because their outputs are subjective; how would you define an ideal response?
There are different strategies for evaluating generative language models and each one will likely be suited to a different use case. You may want to evaluate the truthfulness of the model's responses (i.e. how accurate are its responses by real-world factual comparisons) or how grammatically correct its responses are. For translation solutions, you are more likely to measure metrics such as the Translation Edit Rate (TER), that is, how many edits must be made to get the generated output in line with the reference translation.
Language libraries like LangChain provide features for evaluating the responses according to relevance, accuracy, fluency and specificity, as well as giving you the flexibility to define your own criteria for evaluation via the LangChain API.
Data Outputs
Are you gaining insights from data or generating data?
Clarify whether your intended solution would process and analyse existing data or generate new content. For cases where you want to identify patterns or predict future behaviour, a model that processes data will be well-suited. Examples could include a solution to analyse existing customer data, from which trends can be identified and form predictions.
Data generation solutions, on the other hand, are used to create data that did not previously exist. This new data could take the form of synthetic data that can then be used to train and test machine learning models, or even new creative content, such as text or images.
There is also the option of using a solution that is capable of both processing and generating data. This type of solution can be advantageous in cases where you want your model to learn from its experiences and the data that it is processing. An e-commerce organisation may train a model on a large data set of user behaviour to learn about customers interests. Once this training is completed, the model could then be used to generate new recommendations for users.
Model Selection
What model should you use?
The core component at the centre of a machine learning project is a trained model, which in the simplest terms is a software program that, once given sufficient training data, can identify patterns and make predictions. Your final consideration, therefore, should be how you will access a model for your AI/ML project. In the following sections we will look at two popular approaches for accessing a machine learning model.
With a better understanding of the key considerations for getting started with AI projects, your organisation will be able to evaluate these approaches in line with your intended data area and output.
Approach I - Cloud Services
AI cloud services enable organisations to rapidly adopt and leverage AI technology by providing pre-built models, APIs and infrastructure. Because of the wide range of pre-built models that cloud services offer, it can be useful for organisations to first think if they can achieve their objectives using a cloud service that already exists.

Azure, Google Cloud and AWS provide pre-built, pre-trained models for use cases such as sentiment analysis, image detection and anomaly detection, plus many others. These offerings allow organisations to accelerate their time to market and validate prototypes without an expensive business case.
Where previously machine learning projects have required specialised expertise and substantial resources, AI cloud services enable organisations to quickly develop AI solutions for a range of applications.
In this section:
- How to get started
- Benefits
- Considerations
How to Get Started
- Choose a cloud service provider: Evaluate cloud service providers Azure, Google Cloud and AWS to determine which platform aligns best with your project requirements and budget. Your organisation may already use Microsoft, Google or Amazon products elsewhere and, therefore, choose to align this choice with your existing stack.
- Select the relevant services: Identify the specific cloud services that match the needs of your project. For example, if you're working with language, you might choose Azure OpenAI Service or AWS's Amazon Comprehend. If you are dealing with images, then Azure Custom Vision or AWS Rekognition.
- Preparing and aggregating data: This may involve aggregating and structuring the data to ensure it is suitable for the chosen service. For certain services, like Azure Cognitive Services for Language, a crucial concept is the notion of "utterances" and "intents". Utterances are the phrases that users might use to interact with the system, while intents represent the meaning or purpose behind those utterances. If you are using a computer vision service like AWS Rekognition or Azure Custom Vision, this process may involve collecting a diverse set of images that are representative of the target object.
- Data cleansing: It is important to clean the data to eliminate any inconsistencies or irrelevant information that could impact the analysis. For services involving natural language processing and understanding, pre-processing and standardising text data is important. This process might involve removing punctuation, converting text lowercase, and addressing common abbreviations.
- Build and train your model: Use the cloud service's tools and APIs to build and train your AI model. Certain services provide the choice of selecting a pre-trained model. Azure OpenAI Service, for example, gives users access to many different models such as GPT-4 and DALL-E.
- Test and evaluate: Test your AI model using sample data to ensure it is performing as expected. Evaluate its accuracy and performance. This could be done by comparing the model's predictions against known ground truth labels or by using validation datasets.
Benefits
- Scalability: These services can be scaled up or down according to the resource needs, a particular advantage for organisations who may need to handle or generate large amounts of data.
- Reduced time and cost to set up: Many of the models provided in these services come pre-trained and pre-built, which saves time and effort setting up AI capabilities from scratch.
- Lower entry point: Users do not require extensive technical expertise to use these services. Azure, Google Cloud and AWS provide intuitive interfaces and tools to further simplify the process of creating AI solutions.
- Security: Users are afforded the security features of leading cloud providers Azure, Google Cloud and AWS, such as data encryption, access control and integrations for automating security tasks. Azure has the most certifications of any cloud provider.
Considerations
- Level of customisation: AI cloud services do not give the same level of customisation that you would get from configuring or building your own model. For use cases like language translation and image detection, pre-trained models may suffice. However, if you’re working on a more complex problem that would benefit from more fine-tuning of your model and the training process, then these services may not provide the same level of control as configuring or building your own model. Fully evaluating your use case will give a clearer idea of which approach will be best suited to your organisation.
- Costing approach: Azure, Google Cloud and AWS offer their services through a pay-as-you-go model. While this is beneficial in that it enables you to only pay for what they need, organisations should carefully manage their usage to avoid unexpected costs. One way this consideration can be addressed is by utilising cost management tools such as Microsoft Cost Management or AWS Cloud Financial Management. Cost optimisation strategies, such as using reserved instances or spot instances for non-time sensitive workloads, can also be helpful for reducing unexpected costs.
Approach II - Defining Your Own Model
In cases where you want more control over the development and training of your own model, it can be useful to leverage a machine learning framework like TensorFlow or PyTorch. These frameworks offer libraries and tools to help develop machine learning models.

Building a machine learning model generally refers to the entire process of creating a model from scratch, including selecting an appropriate algorithm or architecture, defining the model's structure and implementation.
Defining a model, alternatively, will more likely involve working with a model from a library or using a framework that provides predefined architectures. Which approach you take will be determined by your organisation's use case, resources and the granularity with which you want to create a model. Building from scratch affords even greater customisation and control over your model but will come with higher financial and computational costs.
In this section:
- How to get started
- Benefits
- Considerations
How to Get Started
-
Decide between using an existing model or developing your own: Consider whether an existing model already addresses your problem. PyTorch, TensorFlow and Scikit-learn offer functionality that can be leveraged for everything from data pre-processing and feature engineering to model training and evaluation. The versatility and power of these frameworks makes them a very viable option if you are choosing to configure or develop your own model.
-
Select a framework: Scikit-learn is a powerful framework for accessing pre-built models or developing custom models across a range of algorithms including classification, regression and clustering algorithms.
Working specifically within the area of neural networks, it is possible to develop custom deep learning algorithms using frameworks such as PyTorch or TensorFlow, developed and used by Meta and Google respectively. These deep learning models can then be used to power solutions such as virtual assistants and speech recognition systems. Both these frameworks are built upon the concept of tensors, which can simply be thought of as multi-dimensional arrays.
Both are mature and stable frameworks, each with their strengths and weaknesses. For example, being heavily used in research areas, PyTorch can provide more access to state-of-the-art models, where as TensorFlow in certain scenarios can provide increased performance due to it's ability to take advantage of GPUs and other specialised processors.
For organisations approaching this with experience in the Microsoft technology stack, ML.NET is also an option with seamless integration capabilities. However, compared to other development frameworks, ML.NET has a more limited set of pre-built models and algorithms available.
-
Aggregating, cleansing and preparing data: This involves collecting all the data that you will use for training your model. Once this data is collected, it will need to be prepared for training, with processes like cleansing being important in getting the data into a format which the data can understand and learn from.
-
Defining your model: Developing and tuning your model is a crucial step in this process and goes beyond simply defining the structure and design of the model. This will require choosing the appropriate algorithms and layers to make your model as effective as possible.
When it comes to selecting parameters, be sure to carefully consider their impact on the model’s performance and ability to generalise. Experimentation and iteration are key in finding the optimal configuration for your specific problem.
In this aspect, PyTorch and TensorFlow are very useful frameworks in that they give you access to a variety of libraries and tools that make it easier to, for example, define neural networks and apply optimisation techniques. Frameworks like Scikit-learn also offer a diverse set of algorithms for traditional machine learning tasks.
-
Training your model: This is where you provide your model with the data it needs to learn. Keep in mind that how long this will take vary greatly, ranging from minutes to months, depending on the complexity of your model and the size of your dataset. This step can be the most time and resource intensive, so it is a good idea to capture the usage metrics of this stage before deploying your model to any production environments.
-
Evaluate your model: Your model will need to be evaluated on a held-out dataset after it has been trained. By doing this, you can determine how well the model generalises to unseen data.
-
Deploy your model: When you are satisfied with the model's performance, you can deploy it in production, which could be anything from hosting the model with API access to embedding the model within a cloud-based web application.
At this stage it is important to consider the type of inference required for your specific use case: real-time or batch inference. Batch inference processes large batches of data periodically. This approach can support complex models and producing results with latency.
These factors make it suitable for situations where you need to produce large batches without requiring immediate results. If you are working in scenarios such as data analysis or generating reports where the focus is on comprehensive analysis, rather than real-time decision-making, then batch inference can be a useful solution.
Real-time inference, alternatively, delivers a small number of inferences instantly. Fraud detection and recommendation systems are two well-suited use cases for real-time inference because they require instant predictions to respond to dynamic situations. One caveat when taking this approach is latency constraint. Real-time inference is less suitable for deploying complex models that require extensive computational resources or have longer processing times.
Benefits
- Control: When you define or build your own model, you take charge of its entire lifecycle. This control allows you to continuously update and enhance the model as new data becomes available. You are not dependent on external providers or constrained by rigid frameworks if you are building your model from scratch.
- Understanding your model: The models used in AI cloud services are sometimes referred to as "black boxes" because they lack transparency. However, when you define your own model, you gain a deeper understanding of its inner workings and can interpret its behaviour more accurately. This level of interpretability becomes especially valuable in domains where transparency is crucial, such as healthcare or finance.
- Flexibility and customisation: Machine learning frameworks provide a variety of algorithms and customisation options that enable developers to tailor models to specific project requirements and data characteristics. TensorFlow, for example, offers a high-level API called Keras that enables developers to build and customise deep learning neural networks.
Considerations
- Expertise required: Defining or building your own model requires a greater understanding of machine learning concepts, as well as the underlying mathematics that support them. An understanding of different algorithms and optimisation techniques can help with important processes such as defining your model and data preparation. However, organisations can still leverage pre-built models with this approach which helps to reduce the expertise required.
- Resource intensive: It is important to have access to sufficient computational resources and ample storage capacity to handle the data required for creating your own model. When it comes to hosting your model, the cloud offers scalable and flexible resources that can handle the computational requirements of training and deploying models.
Hosting a Model
Once your machine learning model has been built and trained, it can be deployed to an environment. Here we will outline a few of the different options available for hosting your model. Which option is best for your organisation will depend on specific budget, needs and overall requirements.
Cloud
Cloud hosting is a popular choice for hosting machine learning models because of the scalability and security that this provides. Here resources are accessed online which allows you to allocate and adjust computational resources based on the demands of your model.
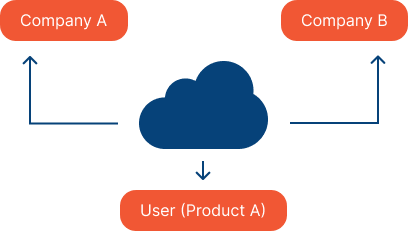
If you’ve developed a model using an AWS or Azure AI service, then your model will be seamlessly integrated with the cloud infrastructure. These providers offer specialised machine learning services that handle the underlying infrastructure and provide built-in scalability.
This scalability makes it easier to host both real-time and batch inference models in the cloud. With cloud hosting, you can allocate and adjust computational resources based on the demands of your model, whether it requires immediate responses or periodic processing of large data batches.
Scalability is accommodated by pricing which operates as a pay-as-you-go service. This means that you only pay for the resources that you need and will effectively have access to unlimited storage, as your budget allows.
One thing to be mindful of is that the creating and running of a machine learning model can be CPU intensive. For this reason, it is advised that you separate out the infrastructure such that you have a dedicated resource running your model. This will prevent the model from competing with other services, like your website or database.
On-premises
This option involves hosting your model on-premises in physical servers. A big drawback here is the maintenance required for these physical servers, which incur large costs and can lead to diminished returns in the long run.
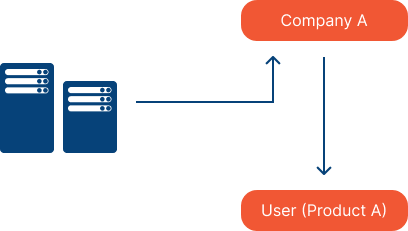
Also consider the infrastructure requirements and maintenance challenges when hosting a real-time inference model on-premises. Unlike other hosting options, real-time models demand continuous availability and low-latency processing. This means you'll need robust hardware, reliable network connectivity and dedicated resources to handle the high volume of incoming data and to be able to provide real-time responses.
Hosting your machine learning model on-premises comes with upfront costs for hardware infrastructure, but it does provide a major advantage if your model is meant for internal use. If you keep the model within your own infrastructure, you will have complete control and ownership over your data. This is crucial when dealing with sensitive information that should remain on-site. This approach will also enable faster data access and reduced latency, in turn, leading to a more responsive system where teams can quickly retrieve data.
Containers
Using containers allows you to package your model and its dependencies into a single unit that could be run on any compatible infrastructure. This could be based within a certain App Service or deployed on a Kubernetes cluster, depending on your specific requirements.
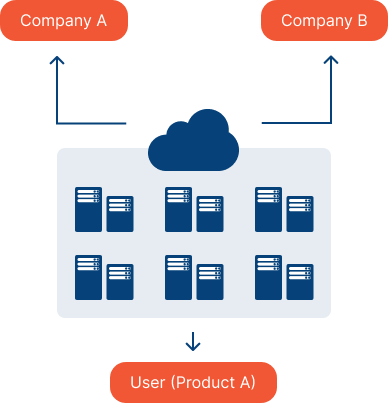
Your model can be packaged along with its associated software stack and deployed seamlessly across various platforms. This portability means that containers make it easy to deploy models to the cloud or on-premises. Containerisation offers some of the similar benefits of hosting in the cloud, such as scalability and flexibility. These benefits also make it suitable for hosting both batch inference and real-time inference models.
However, if your organisation has limited hardware infrastructure or a limited budget for hosting containers, the cloud may offer a more cost-effective solution.
Maintaining and Retraining Models
With your model deployed, it is important to consider how you can maintain and potentially improve its performance through retraining.
Data changes over time, and what was valid or representative a few years ago may no longer hold true today. If you have a model that predicts user behaviour, six months of user behaviour data from three years ago may no longer accurately reflect current patterns.
It is, therefore, important that you effectively maintain and retrain your model to ensure accuracy. Here we outline six key areas to consider during these processes:
- Decide a plan to feed in new data
- Investigate failures
- Leverage tools to improve your algorithm
- Retraining does not guarantee better performance
- You might get better data over time
- Perform actions periodically
1. Decide a plan to feed in new data
Determine the schedule and approach for feeding in new data and retraining your model. This could be on a time basis (weekly, monthly, etc.), per-deployment or event-driven triggers. Setting this plan early ensures that your model stays up-to-date and can adapt with evolving patterns.
2. Investigate failures
Investigating very bad failures or inaccurate results may identify parameters that you had not previously considered. For example, in a database looking at vehicles, these results may identify attributes like engine size or maintenance history, that had not previously been factored into the model. You can then add this previously unconsidered factor as a parameter in your model and retrain it to see their impact.
3. Leverage tools to help improve your algorithm
There are various tools that you can use to improve your algorithm by fine tuning parameters and optimising performance. One example is Ray Tune, a Python library that provides capabilities for tuning hyperparameters. This allows you to automate the process of exploring different hyperparameter configurations and finding the optimal settings for your model.
Running tools like these periodically gives organisations insights into how they can improve data collection and overall business processes, in turn, leading to a better model. The objective, here, is to seek out opportunities for getting more accurate results from your machine learning solution, so that it can respond to the latest market and customer data.
4. Retraining does not guarantee better performance
Without proper evaluation, retraining might give you a worse model. Be sure not to save a model without first ensuring that it is performing better than older models. It is recommended that you retain your own criteria for what constitutes a good model and archive previous models to maintain access to them.
For example, an outlying piece of data might cause your retrained model to perform badly. In this case, it is important that you can still access your last model for comparison and fallback purposes. Archiving older models will ensure that you always have a reference point to determine how effective your retraining process is and avoid a regression in performance. This way you won’t be replacing an older model that is performing better than your retrained model.
5. You might get better data over time
Over time, training data can become less relevant or redundant. The likelihood is that there will always be ways that you can get better data for your model. This does not necessarily mean that your existing data is ‘bad’, but rather that there may be opportunities to enhance the quality, diversity or fullness of the data.
An important step here is to establish a learning curve. This is a graphical representation of how your model is performing related to the amount of training data that it receives. Analysing the learning curve can help you gain insight into how the model’s accuracy or other performance metrics change as you increase volume or variety of training data.
6. Perform actions periodically
Measuring the performance of your machine learning model periodically ensures that you are consistently monitoring its effectiveness and scoping out any potential areas for improvement. Utilise your learning curve perhaps every quarter or at regular intervals depending on how quickly your data changes, to assess the model’s performance over time and identify trends that may require your attention. You may discover that your model would benefit from additional training data to enhance its performance.
Appendix 1 - Example Cloud Service Architecture (Azure AI)
Cloud service providers including Google Cloud, AWS and Azure provide a range of services that enable organisations to get started developing AI solutions quickly. These services include pre-built and pre-trained models, APIs and other important tools for solving real business problems.
Focusing on Azure, here we breakdown the three main categories of Azure AI cloud services:
- Azure Machine Learning
- Azure Cognitive Services
- Azure Applied AI
Azure Machine Learning
A space for data scientists and developers to upload, train and host machine learning models.
Azure Machine Learning is a fully managed cloud service for building, training and deploying machine learning models. It provides a variety of tools to help you with every step of the machine learning process, from data preparation to model training and deployment. With its robust set of tools, this service can be leveraged by organisations to solve a wide variety of problems.
Azure Cognitive Services
Pre-built and pre-trained models.
Azure Cognitive Services are a set of pre-built APIs and SDKs that enable you to add features like natural language processing, speech recognition and computer vision to their applications. These services provide the foundation for more advanced Azure AI Services, such as Azure Applied AI Services.
Azure Applied AI Services
Pre-built solutions.
Azure AI Cloud Services Breakdown
View our interactive breakdown of all Azure AI cloud services below, with descriptions and use cases.
Jump to our industry case studies on organisations leveraging Azure AI cloud services for everything from image classification, to natural language processing.
Azure Services
Download PDFAppendix 2 - Industry Case Studies
With an understanding of the machine learning cycle established, this section will look at how leading organisations have created powerful machine learning solutions by leveraging cloud services or defining their own model using a machine learning framework.
1 - Planning Optimisation
Leveraging combinatorial optimisation models to solve task scheduling problems.
Approach: Configuring a model
Technology: ML.NET
Client
The client for this project is a global provider of sterilisation of medical products. The main objective of the project was to create an application that could accurately forecast the optimal efficiency of the sterilisation process.
An application was created using ML.NET to accurately predict the dose range for products undergoing sterilisation. The prototype, trained on the provided data, leveraged machine learning algorithms within ML.NET to predict the level of sterilisation required for products prior to product loading.
This machine learning framework was chosen because it aligned with the organisation’s technology stack, meaning that it could be seamlessly integrated with their other .NET applications.
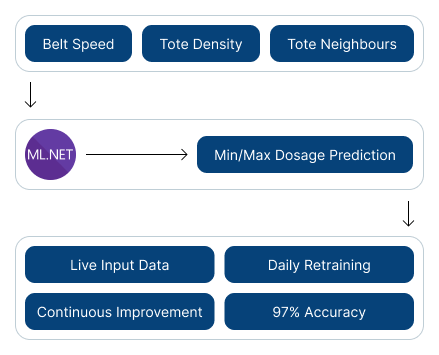
Selecting the model
The first step in building the model was to define the scenario that we wanted to solve. A key feature that helped with this process is the ML.NET Model Builder, which selects the algorithm that will perform best on a given data set. This feature helps developers get started on building their model without the need for extensive algorithm selection and evaluation.
Working with the data
Historical data that could be used to train the model was provided and imported into the model. The range of file types supported by ML.NET, including CSV files and SQL Server databases, made this a seamless and efficient process. The historical data could then be used to build a customised linear regression model in ML.NET.
Training and testing the model
An LGM algorithm was selected for training and testing the model. This is a type of linear regression algorithm that is useful for predicting a single value based on a set of input parameters. The parameters for the model were density, totes, surrounding totes' density and processing speeds. This model was trained locally, although ML.NET also offers the ability to train models on Azure as well. Trained using approximately 6,000 runs, the platform quickly learned and adapted to the data.
Retraining the data
Functions like Test and Evaluate helped ensure that the model was accurate and performing as expected. These functions enabled the model to be tested on unseen data and helped evaluate its performance by providing metrics related to accuracy and precision.
How it works
This tool can calculate the probability of achieving the desired sterilisation range for a given set of processing speeds. This flexibility helps optimise scheduling and dosage processes while ensuring compliance with contractual obligations.
All results provided by the predictor are made available to scheduling administrators who can then make informed decisions based on the predicted range. The tool empowers users to assess the probability of failure, for instance, by indicating that processing the solution at a certain speed had a 90% chance of failure. Users have the final say in processing decisions and can infer the likelihood of failure by processing the product under different conditions.
The benefits
The predictor not only enhanced existing processes but also provided scheduling administrators with data-driven insights to optimise their decision-making. The project highlighted the power of ML.NET to create custom machine learning solutions quickly and with great accuracy. Further successful outcomes included:
- Accuracy and compliance: The predictor delivered exceptional results, achieving over 97% accuracy.
- Faster prototyping: ML.NET enabled rapid prototyping without the complexity of using traditional programming languages like Python, C++, or Ruby.
- Flexibility and iterative development: ML.NET offered the flexibility of training the dosage predictor both locally and on Azure resources. This flexibility ensured that the client could leverage the optimal resources to create a robust and high-performing dosage predictor.
2 - Outlier Detection and Classification
Using SVM models to detect inaccurate or overestimated energy bills.
Approach: Defining a model
Technology: Scikit-learn and Panda
Client
The client for this project is a nationwide energy provider who specialises in providing gas to organisations. The main objective for this project was to be able to better predict incorrect or overinflated estimates for energy bills.
By accurately predicting these bills, the organisation could improve billing transparency, in turn, ensuring that customers could avoid unnecessary expenses. A machine learning model would provide a data-driven approach to the billing process and help increase customer service and trust in the long term.

Selecting the model
The scikit-learn library and panda open source package in Python was used for this project as it provided the necessary tools and resources to preprocess and analyse the data.
A linear support vector machine (SVM) model was specifically chosen for its ability to handle complex patterns and relationships in data effectively. SVMs are particularly powerful for identifying outliers and classifying data into different categories, which made them well-suited for distinguishing potentially inaccurate bills in the data.
Working with the data
Historical data was provided by the organisation relating to customer data, billing details and energy consumption metrics. Most useful was the data revolving around what an accurate bill should look like. This subset would serve as a reference point for distinguishing between correct and incorrect or overinflated estimates.
This data then underwent thorough preprocessing, including cleansing and transforming the dataset, to ensure that inputs were meaningful and could be effectively used for training the model.
Training and testing the model
Scikit-learn provided a comprehensive implementation of linear SVMs which helped ensure a seamless process for training the model.
The model was thoroughly trained using supervised learning methods and labelled data. Each data point had input features and a corresponding label indicating whether the estimate was incorrect or overinflated.
This allowed the model to learn the underlying patterns and relationships between the input features and the billing errors. The model’s parameters were fine-tuned throughout this process, with a focus on optimising its performance to ensure the highest possible accuracy.
Two days of training resulted in strong levels of accuracy for the model. Key to this success was defining what an ideal bill looked like in the data. This meant establishing the characteristics of what was an accurate bill, so that the model could gain a deep understanding of what constituted an incorrect or overinflated estimate.
Retraining the model
The model was retrained periodically to adapt to evolving data patterns and changes in energy billing practices. Using updated data for this retraining helped to improve the accuracy of the model and ensure its effectiveness in predicting incorrect bills.
How it works
The solution developed predicts incorrect or overinflated estimates for energy bills to a high level of accuracy by analysing input features and identifying patterns indicative of such errors. With these predictions, the organisation can take corrective measures and provide more accurate billing information to customers.
The benefits
Scikit-learn provided ideal functionality for this use case, with functionality that enabled seamless machine learning development. Main benefits of using this library included:
- Flexibility: The flexible nature of the Scikit-learn enabled effective experimentation with different model parameters and techniques. Adjusting these areas helped ensure that the model was as performance accurate as possible.
- Accessibility: As a widely used machine learning library, scikit-learn provided an accessible and intuitive interface which made the process of building the predictive model more streamlined
3 - Image Classification
Leveraging AI cloud services to identify product images within supermarkets.
Approach: AI Cloud service
Technology: Azure Custom Vision
Client
This organisation faced a challenge of monitoring the placement of their products in supermarkets to ensure optimal visibility for their brand. An ideal solution to this situation would give a more streamlined and automated solution to capture product images and compare their shelf presence with competitor products.
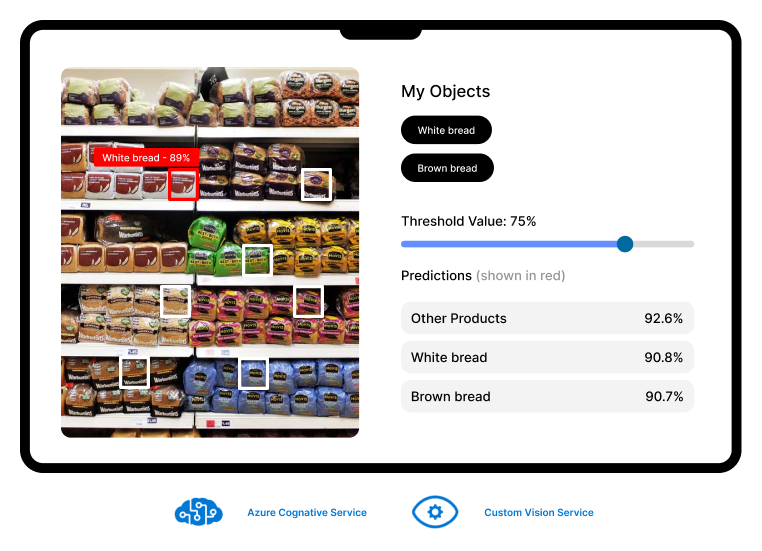
Solution
Azure Custom Vision, a part of Azure Cognitive Services, was used for this project because it provides built-in functionality for identifying food on shelves. Azure Custom Vision provides granular functionality for choosing what machine learning you want to create, categorised into:
- Project Types: Allows users to select whether they want to classify images (Classification) or detect objects (Object Detection). The Object Detection Project Type was leveraged in this project to train the Custom Vision model to recognise individual food products.
- Classification Types: Distinguishes between Multilabel or Multiclass. Multilabel means that any number of tags can be applied to the images, whereas multiclass organises images into single categories. This means that most of the images that are uploaded will be organised into the most likely tag.
- Domains: Particularly useful is the extensive list of domains that Azure provides. Users can select from this list to focus their solution around one area of computer vision. Azure already has a base model that has received a lot of data on how to identify images of, for example, food, landmarks and other areas.
Gathering data
The project began by collecting photographs of the client’s products on supermarket shelves. While there was the option to use pre-trained models within Custom Vision, in this case the model was manually trained with a wide selection of images taken from different angles. This decision was made to ensure that the model could recognise specific characteristics and variations of the product. The training data also served as test and validation data and provided a starting point for the model to learn and improve.
Labelling the data
With this data collected, each image was then tagged with relevant labels and classifications that could differentiate the products. Custom Vision ensured an efficient labelling process by automatically detecting potential products within the image that could then be labelled with our created tags.
Training the model
Custom Vision provides granular control over how you want to train your model. This includes training type — whether you want to carry out quick training or advanced training on your model — and for how long you wanted to train your model. Azure provides indicators to show how certain the duration of training time corresponds to budget.
Improving the model
Custom Vision provided the flexibility required for refining this solution. With a Quick Test, you upload an image an image that the model can process. Results from this test are split into three metrics: Precision, Recall and mean Average Precision (mAP).
The service also allows you to improve your model by conducting a quick test and querying the detections made by the model, e.g. correcting the model if it wrongly identifies a tub of greek yoghurt as a pint of milk. This evaluation allowed for continuous improvement by identifying misclassifications and providing feedback to the model, gradually enhancing its accuracy.
Benefits
Custom Vision enabled the creation of a proof of concept by creating, training and refining an image detection model. The implementation of Azure Custom Vision provided the client with a clear proof of concept for how an AI solution for product image detection would behave. Other benefits include:
- Speed: Within a day of training, the Custom Vision model demonstrated confident recognition of the client’s products on supermarket shelves. This result demonstrated the power of Azure Cloud Services for quickly developing and testing the feasibility of machine learning solutions.
- Ease of use: Custom Vision provided an accessible interface that helped during the process of refining and adjusting the model. These advanced training capabilities could then help to ensure accurate product image detection.
4 - Custom Software Builder
Leveraging LLMs to create an onboarding virtual assistant for custom software builds.
Approach: AI cloud services
Technology: Azure OpenAI Service
Client
Low- and no-code platforms allow non-technical users to build powerful projects quickly and efficiently. However, the traditional process of building a project within these platforms often involves manually adding data to tables and their associated rows. This manual approach not only consumes significant time and effort and for more complex projects requires some knowledge of data modelling. The client for this project is a no-code platform who was looking to streamline this traditional process for building projects.
Solution
The solution streamlines the onboarding process for the client by giving users a way to quickly generate projects based on text inputs. This eliminates the need for manual data entry and reduces the time and effort required to get started with a new project.
Microsoft’s Azure OpenAI Service was chosen for this project because it provides access to OpenAI’s pre-trained large language models, including GPT-3 and Codex, via its REST API. This API can then be leveraged to create generative language processing tools. Azure OpenAI Service is also compatible with open-source framework LangChain to allow users more granular control over the training of these large language models.
Writing the prompt
Prompt engineering is a key part of how Azure OpenAI Service functions. This process requires users to input queries to the machine learning model to elicit desired responses. Prompts should be detailed enough to guide the model towards generating an accurate and contextually appropriate response. The completions endpoint is the key area of the API to submit prompts. Here users can provide an input command and the model will generate a text completion. Prompts can range from a short piece of text that provides context for the completion, to a maximum number of tokens, which defines how big the completion should be.
Azure OpenAI Service provides a playground to experiment with these capabilities. Here users can interact with the API and adjust various configuration settings, such as the temperature and length of the generated text. To familiarise the API with the no-code platform, detailed information about the platform, its capabilities and its use cases were provided to the completions endpoint. This information gives the model an understanding of the platform and the project creation process. Key information included context about what features the platform offers and data relationships that can be created on the platform.
Azure OpenAI Service is particularly powerful because of its ability to quickly gain an understanding of the context that is provided. Leveraging OpenAI’s generative language model, ChatGPT, the completions endpoint responded to text inputs with relevant data types and relationships.
Executing the prompt
The API was also able to return an accurate JSON array based on the project database, name and description. This code contained all the data types each table, as well as the necessary data relationships that have been suggested by the model. This code can then be parsed and used to dynamically create the tables and fields required for the CRM platform.
The API also made it easy to integrate the developed solution with the client’s platform, ensuring a seamless end-to-end user experience. Once the prompt is executed, the API provides a JSON array that can be linked through as part of an interactive UI.
Results
Azure OpenAI service given users the ability to build custom software solutions by interpreting and processing natural language text inputs. For example, by interreacting with the AI and providing a request like “I want a CRM platform” users will receive a custom CRM platform to fit their needs. This approach revolutionises the traditional process of building these platforms, as it eliminates the need for extensive business and process analysis. Other benefits of using the platform included:
- Access to large language models (LLMs): : OpenAI Service leverages OpenAI’s most powerful language models such as ChatGPT and GPT-04, enabling users to create powerful natural language processing tools.
- Speed: The API contained within Azure’s OpenAI Service reduces the chances of bottlenecks compared to using OpenAI’s API, where users would be contending with the traffic from ChatGPT.
- Content moderation: Azure OpenAI includes a content management system that filters potentially harmful content alongside the models. For detecting misuse, this system runs both input prompts and generated completions through a series of classification models.
- Security: OpenAI service comes with enterprise-grade security features, such as role-based and access control.
5 - AI WhatsApp Chatbot
Leveraging NLP to create an AI WhatsApp chatbot for improved customer service.
Approach: AI cloud services
Technology: Azure Cognitive Services Language Studio
Client
The client for this project is a major UK train operator, providing services across multiple regions and connecting key cities, playing a vital role in daily transportation and commuting for thousands of passengers.
The client was experiencing a high volume of customer service enquiries related to journey planning. Passengers frequently required support not only for train journeys but also for reaching their final destinations, including arranging onward transport in remote locations.
Recognising the need to enhance customer service while reducing the workload on support teams, the company sought an automated solution that could deliver real-time journey information, signpost relevant assistance services, and handle general customer requests efficiently.
The main objective of this project was to develop an AI-driven tool that could automate customer interactions, ensuring a seamless experience while freeing up teams for more complex queries.
Solution
Azure Cognitive Services, specifically the Language Studio component, was chosen as the preferred technology for this project due to its advanced conversational language understanding capabilities and ease-of-use.
Azure Cognitive Services is a part of the Azure AI Cloud Services, and its Language Studio component provides a robust and intuitive platform for building, training and deploying language models.
This tool also aligned with the client’s existing technology stack, which would give them the flexibility to integrate the solution with other technologies in the future. The chatbot was built by creating intents and utterances that define how the model processes customer requests.
This chatbot was designed to:
- Provide real-time train departure and arrival information.
- Recognise and respond to journey planning requests.
- Offer contact details for local taxi operators at destination stations.
- Support additional customer service needs, including enquiries about disruptions, complaints and refunds.
Adding data
The data input process into Language Studio involved creating intents related to requests for journey planning:
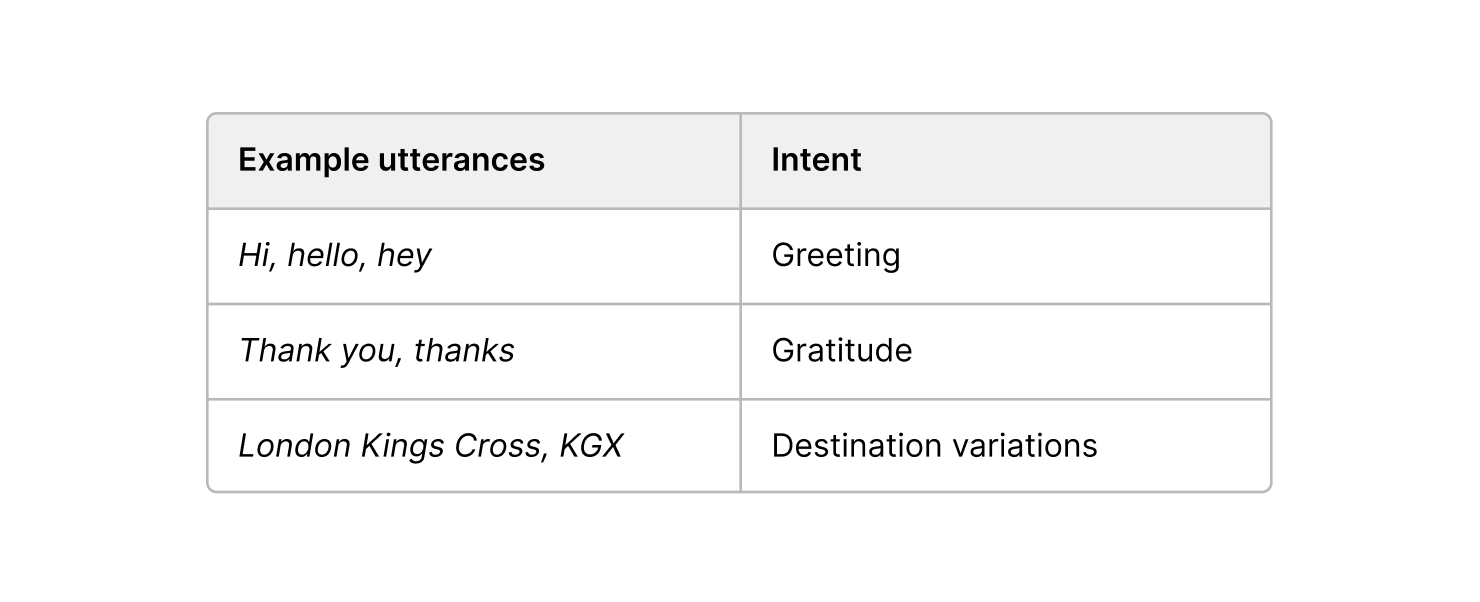
Labelling the data
Language Studio requires labelled examples to improve its understanding of these utterances. At this stage an example utterance was provided, and relevant entities were labelled (e.g. departure destination and arrival destination). The model is then able to gain a better understanding of the different entities that make up each request.
For this project, state management was implemented in order to deliver a customer experience that replicated the service provided by the support team. Conversation context is handled manually in code, which enables the model to more accurately the context of the ongoing conversation.
Training the model
Utterances are split into a training set and a testing set. The model uses phrases in the testing set to test whether it can correctly identify entities within an utterance. Users can then monitor model performance according to how accurately it identifies intents and entities.
Language Studio provides the functionality to evaluate testing sets. This allows users to see where the model is struggling to correctly identify entities. This information can then be used to improve the model’s accuracy by refining the utterances and entities within the training set.
For instance, during the evaluation, a noticeable pattern emerged that a significant number of failures are associated with text containing brackets. This issue was proactively addressed by augmenting the training set with additional cases that included brackets in the station names. This approach then facilitated the model’s ability to learn and adapt to such patterns, further improving its performance in handling queries involving bracketed text.
Refining the model
Language Studio’s insights and metrics help to evaluate the model’s recall and decision stats. These features enabled the chatbot to be iteratively refined, in turn, enhancing its accuracy in understanding and responding to user queries. Two training options, basic and advanced are available, with advanced offering greater capabilities at a higher cost and longer training duration.
How it Works
Passengers can interact with the chatbot via WhatsApp, asking questions like:
“When is the next train from Leeds to Manchester?”
The chatbot retrieves live departure information for over 2,500 stations across the UK, leveraging CRS (Computer Reservation System) station codes to interpret queries accurately. Additional features include:
- Website integration for further customer support.
- Real-time service disruption alerts.
- Onward travel assistance by providing local taxi contact details.

The Benefits
The AI chatbot delivered significant improvements in customer service and operational efficiency, supporting over 1 million conversations a year:
- Accessibility: Passengers receive real-time train updates instantly, reducing reliance on customer service teams.
- Improved Journey Planning: Live departure data and onward travel options ensure a smoother travel experience.
- Scalability: The chatbot’s capabilities can be expanded to handle additional queries, such as booking assistance for passengers requiring special support.
Glossary
| Term | Definition |
|---|---|
| Artificial intelligence | The development of computer systems that can perform tasks that would usually require human intelligence. |
| Clustering | A method used in unsupervised learning to group data points together based on their similarities and characteristics. |
| Deep learning | A branch of machine learning that uses artificial neural networks with multiple layers to extract meaningful patterns. |
| Error functions | Metrics that measure the difference between predicted and actual values, used to guide model optimisation. |
| Gradient descent | An optimisation algorithm used to minimise the error of a model by adjusting its parameters iteratively. |
| Human feedback | Inputs provided by humans to evaluate, correct or guide machine learning models. |
| Lemmatisation | The process of grouping together different inflected forms of a word for analysis as a single item. |
| Linear regression | A statistical approach for modelling the relationship between dependent and independent variables using a linear equation. |
| Logistic regression | A statistical technique used to model the probability of a binary outcome based on independent variables. |
| Machine learning | An application of AI that enables machines to learn from data and improve their performance without explicit programming. |
| Model | A representation of a real-world system or process created by a machine learning algorithm to make predictions or decisions. |
| Natural language processing | The field of AI focused on enabling computers to understand, interpret and generate human language. |
| Neural networks | Computational models that consist of interconnected nodes or neurons that can learn and make decisions. |
| Overfitting | A phenomenon in machine learning where a model becomes too specialised to the training data and performs poorly on new data. |
| Pre-trained model | A model that has already been trained on a dataset. These models are built to perform specific tasks, such as image recognition. |
| Recurrent neural networks | Neural networks that can process sequential data by including loops within their architecture to retain and utilise past information. |
| Reward functions | Functions that define the measure of success or desirability in reinforcement learning, guiding the learning process. |
| Sequence transduction | The process of transforming one sequence of data into another sequence (e.g., translating one language into another). |
| Stemming | A text processing technique that reduces words to their base or root form to simplify analysis and improve efficiency. |
| Supervised learning | A category of machine learning where models are trained using labelled data to make predictions or classifications. |
| Unsupervised learning | A category of machine learning that trains models on unlabelled data to identify patterns or structures. |
Download
Get your copy of the guide by filling in the form below.
If you have any issues downloading the guide, please email marketing@audacia.co.uk

